
Post-mortem on the Crowdstrike incident

CrowdStrike is a cybersecurity company that produces a suite of security software products for businesses to protect their computers from malware.
A vulnerability scanner produced by CrowdStrike, Falcon Sensor, detects and prevents threats by monitoring operating systems at the kernel level. As is usually the case with software, updates are regularly dispatched to address new threats and offer new features.
This time, however, the update resulted in widespread system crashes on Windows devices.
On July 19, 2024, at 04:09 UTC, CrowdStrike released a modification to a configuration file responsible for screening named pipes (Channel File 291). This caused an out-of-bounds memory read, effectively crashing the auto-updated machines.

Photo Credit: AP
Windows virtual machines on the Microsoft Azure cloud platform began rebooting and crashing immediately, prompting the company to revert the release at 05:27 UTC. Devices that booted after the revert were not affected.
Most personal Windows PCs were unaffected, as Falcon Sensor is mainly used by organizations. MacOS and Linux machines were also unaffected.
Following the ensuing panic, CrowdStrike CEO George Kurtz released a statement that CrowdStrike’s faulty kernel configuration file update had caused the problem, confirming at 09:45 UTC that a fix was deployed.
The Pandora Box was opened, however, and system crashes affecting millions of Windows devices caused disruptions to critical infrastructure, including emergency services, air travel, healthcare systems, and other critical business operations across the globe―making it one of the largest IT outages in history.
In the following days, CrowdStrike and other tech companies, including Microsoft and Google, began a thorough investigation into the cause of the outage while providing emergency support to affected customers.
Affected machines could be restored by rebooting while connected to the network to download the latest patches, but the process requiring manual intervention by a technician on each individual machine put businesses down for days―not to mention the additional complexity for remote workplaces or machines with complex security requirements like disk encryption.
Though unrelated, the Azure platform had an outage the day before that blocked some companies’ access to their storage and Microsoft 365 applications in Azure’s Central United States region. This created compounding problems for customers who were, for example, unable to access credentials, knowledge management documents, and other required documentation to fix the problem in the first place.
CrowdStrike apologized for the incident and released a detailed root cause analysis to prevent similar future occurrences, but potential legal actions and economic repercussions for the company are already looming on the horizon.
As organizations and individuals affected by the outage continue to recover and implement measures to prevent similar issues in the future, the cybersecurity industry undergoes a comprehensive review of its practices and standards to improve system resilience. How could such a widespread outage happen in 2024? Before potential new regulations may be introduced to address the risks associated with large-scale IT outages, you need to protect yourself. In this article, we will provide recommendations to prevent similar incidents, but first, let’s look at some interesting facts regarding the impact of such outages.
Impact

Image by Diego Radames/Europa Press / Getty Images
The global cost of the outage was tremendous: companies lost about $10 billion due to lost work time, operational side effects, and emergency costs. Fortune 500 companies lost nearly $5.4 billion because of it, but only a small percentage, between 10 and 20%, will be covered by insurance, according to cloud specialists.
With an estimated 8.5 million impacted systems, the scale is unprecedented, although only accounting for one percent of all Windows devices.
Many industries in the tertiary sector were affected, but also government institutions including emergency services and websites. At the time of the incident, CrowdStrike reported more than 24,000 customers with nearly 60% of Fortune 500 companies and more than half of the Fortune 1000.
CrowdStrike is only minimally liable for lost revenue according to the terms and conditions of Falcon Sensor: the maximum compensation an affected company could recover are the fees that the company has paid to CrowdStrike. CrowdStrike might be held liable under GDPR in the EU as a personal data breach, but it’s unclear whether temporary loss of access to data is enough to trigger liability.
What Could Have Been Done
Crowdstrike’s failure is a typical example of bad practices that remain because of legacy systems and the lack of a proper review process. Affected companies could have protected themselves by following 3 basic first principles:
- An industry-standard deployment process following best practices
- Redundant systems based on proactive risk assessment
- A solid incident response plan
Let’s dive into these principles to understand how they could have prevented the outage.
Lesson 1: Updated review process
A robust review process to identify and rectify vulnerabilities before they become exploitable is the cornerstone of secure software development.
Surprisingly, Crowdstrike’s post-mortem mentions the absence of staged deployment. Continuous Integration and Continuous Delivery (CI/CD) pipelines automate testing and deployment to reduce human error and accelerate development time. However, going from development straight to production is a glaring mistake.
Most companies use a staging environment to test compiled code as close to production settings as possible to avoid pushing breaking changes.
However, there needs to be more than CI/CD. CrowdStrike should have also provided a way for clients to accept or refuse updates instead of forcing their way through the kernel or at least push the update gradually in small batches using canary deployment and/or rolling strategies.
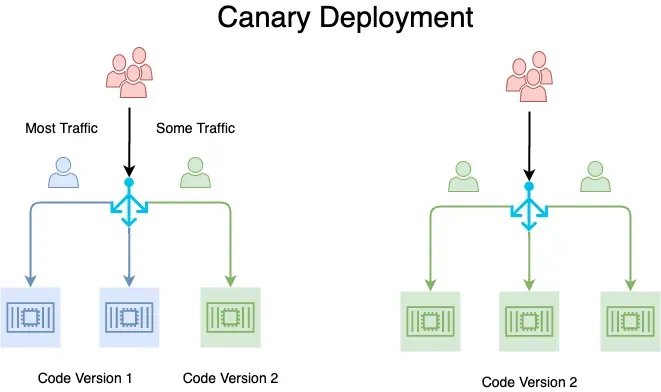
Credit: Abhishek Varshney
While automation is essential, human oversight is indispensable. Regular code reviews and security audits can identify issues missed by automated tools, but at the scale CrowdStrike operates, nothing beats testing in production―as long as you don’t push fresh code to millions all at once on a Friday.
The post-mortem also highlights that necessary input validation checks were missing from the test suite, leading to the out-of-bound memory read at the origin of the crash. Surprisingly, a similar problem had already affected Linux distributions of CrowdStrike software in April 2024. No single testing method is foolproof, and a combination of testing techniques to increase test coverage while considering production usage is required for a more comprehensive assessment.
Lesson 2: Have a plan B
Even with the best test suite, bugs can still occur. As Donald Knuth puts it, “Beware of bugs in the above code; I have only proved it correct, not tried it.” The potential impact of these bugs is significant, making a well-thought-out contingency plan essential for mitigating damage.
Proactive risk assessment is essential for sysadmins and developers: you must regularly evaluate potential threats and vulnerabilities to prioritize risk mitigation efforts. Crowdstrike typically falls into Vulnerable and Outdated Components of the OWASP’s Top 10’s: “You are likely vulnerable if you do not know the versions of all components you use, including […] nested dependencies. If software developers do not test the compatibility of updated, upgraded, or patched libraries.”
Start by identifying critical assets by determining which systems, data, and applications are essential to the organization’s operations, then assess potential threats and their impact on the organization to focus on mitigating high-impact risks first.
Redundancy is not just a concept; it’s a necessity. To ensure continuity in case of a disruption, you need to implement redundant systems and schedule regular backups. This will provide security and preparedness in the face of potential risks.
Microsoft recommended restoring a backup from before July 18 as a way to fix the issue―as long as your Azure storage server was unaffected. There is also certainly a case against centralization to be made here: having your data backups in a single cloud provider is no different than having none at all.
Lesson 3: Incident response plan
On a positive note, Crowdstrike’s incident response plan could be applauded: though it took days for some businesses to recover, a fix was pushed less than an hour after the update, and the CEO acknowledged the issue the same day. Blog posts were also released to explain the situation and warn users about phishing scams.
An effective response plan to a security incident is essential to minimize damage and recovery time. It should outline roles for a dedicated cross-functional team and procedures for communication and escalation.
Clear communication channels facilitate information sharing during a crisis but are also a legal imperative to limit liability. This includes both internal communication within the organization to resolve problems quickly and external communication to interact with customers, partners, and institutions.
It would be best if you also took into account misinformation. Governments and cybersecurity agencies warned of digital phishing scams purporting to be CrowdStrike support and impersonating CrowdStrike staff in phone calls. Training employees and customers to recognize, avoid, and report phishing attacks is part of broader prevention efforts that must be planned as early as possible.
Conclusion
The CrowdStrike Falcon Sensor update exposed critical vulnerabilities in software development and deployment practices. While the company responded quickly to the outage, the impact on businesses worldwide was severe. Businesses can learn a few things from this incident:
- Legacy review processes and lack of robust testing led to a cascading failure.
- Automating deployment is essential but needs to be paired with human oversight and staged rollouts.
- Contingency plans, risk assessments, and redundancy are crucial for mitigating damage.
- Effective incident response plans minimize disruption and legal repercussions.
This incident underscores the importance of secure secret management. Our platform, Onboardbase, is designed to prevent such incidents by securely storing, managing, and rotating credentials and other sensitive data, thereby reducing the risks associated with centralization. Onboardbase seamlessly integrates into your development workflow, maximizing the benefits of CI/CD while addressing the risks associated with the human factor through monitoring and fine-grained access control. Sign up to Onboardbase today to build a more resilient and secure IT infrastructure and prevent future incidents!
Subscribe to our newsletter
The latest news, articles, features and resources of Onboardbase, sent to your inbox weekly